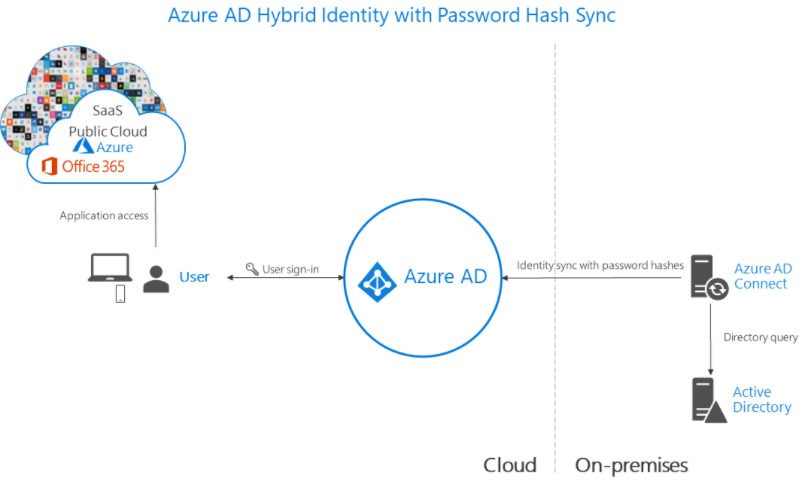
Azure AD is the provider of identity management for Microsoft Azure. It's very important to understand its features and how it works in details to be able to build secure solutions on Azure. While most of what I have written here is also available on Microsoft website, I believe this post will give you enough … Continue reading Understanding The Many Facets of Azure Active Directory
Acquire and historicise data into Snowflake using Fivetran
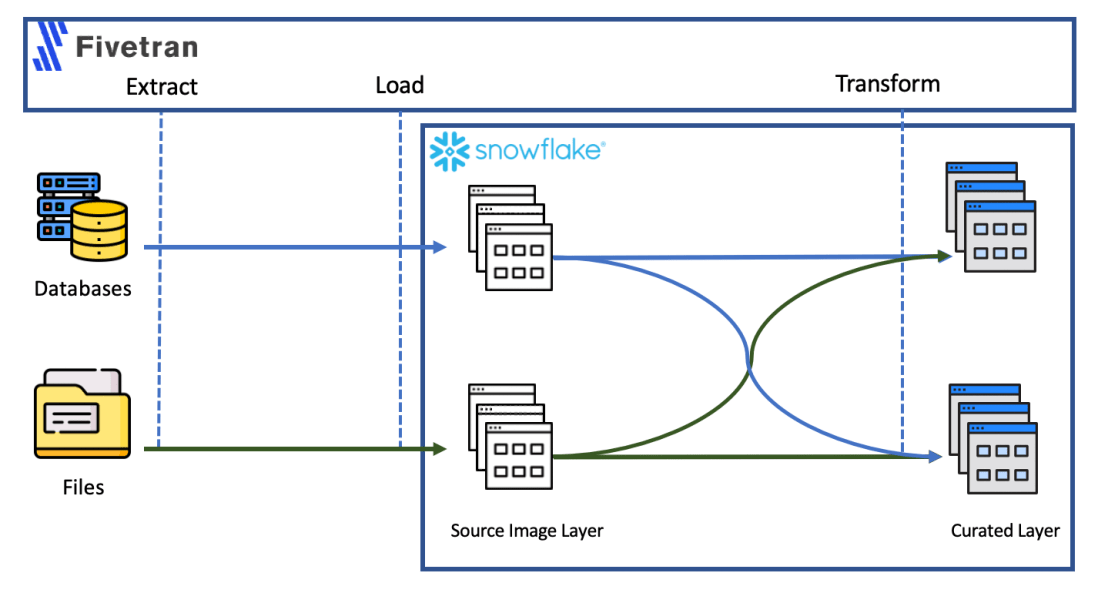
Cloud has become the default choice for many organisations when they decide to build a data platform or modernise their existing ones. Cloud data platforms are so ubiquitous nowadays that even those who used to emphasise on imaginary terms such as "vendor lock-in" can't defend building an on-premise platform from scratch anymore. But not all … Continue reading Acquire and historicise data into Snowflake using Fivetran
An Introduction to Automated Schema Evolution for BigQuery
Everything changes and nothing stays still. Even the source systems generating data across the organisations (shocking!!), which means the schema of the downstream data stores need to evolve accordingly. Schema evolution refers to the ability of downstream systems such as data warehouses to be able to adapt to the changes in the structure of data … Continue reading An Introduction to Automated Schema Evolution for BigQuery
Control IoT Devices Using Scala on Databricks (Based on ML Model Output)

A few weeks ago I did a talk at AI Bootcamp here in Melbourne on how we can build a serverless solution on Azure that would take us one step closer to powering industrial machines with AI, using the same technology stack that is typically used to deliver IoT analytics use cases. I demoed a … Continue reading Control IoT Devices Using Scala on Databricks (Based on ML Model Output)
Stream IoT sensor data from Azure IoT Hub into Databricks Delta Lake

IoT devices produce a lot of data very fast. Capturing data from all those devices, which could be at millions, and managing them is the very first step in building a successful and effective IoT platform. Like any other data solution, an IoT data platform could be built on-premise or on cloud. I'm a huge … Continue reading Stream IoT sensor data from Azure IoT Hub into Databricks Delta Lake
From Monolithic Architecture to Microservices and Event-Driven Systems

I’m a massive fan of streaming and real time data processing and solutions. I strongly believe a lot of use cases are going to be defined and implemented around fast and streaming data in near future, especially in IoT and streaming analytics. With 5G rolling out soon and its superfast bandwidth and wide geographical coverage, … Continue reading From Monolithic Architecture to Microservices and Event-Driven Systems
Use Streaming Analytics to Identify and Visualise Fraudulent ATM Transactions in Real-Time
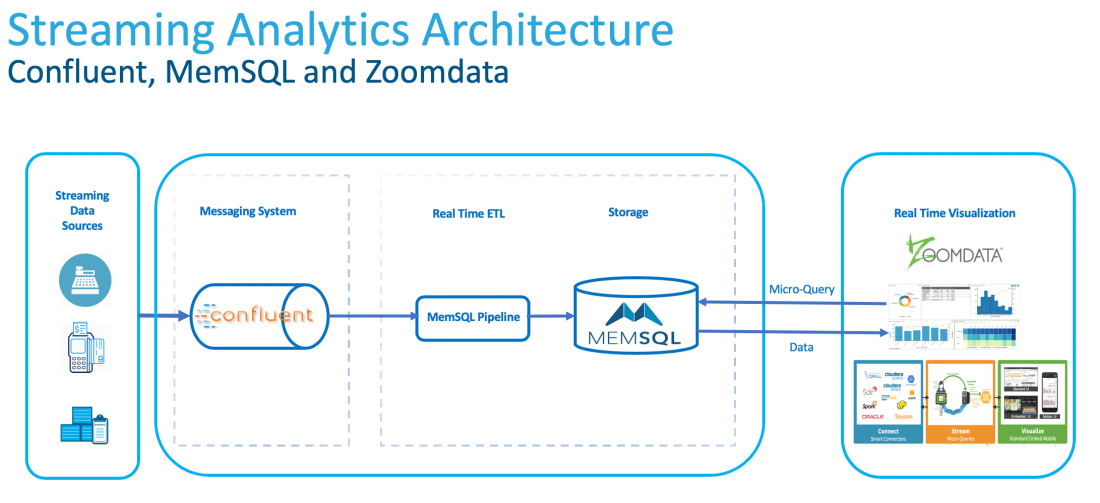
Storing and analysing big amounts of data is not the differentiator of successful companies in the process of decision making anymore. Today's world is about how fast decision makers are provided with the right information to be able to make the right decision before it’s too late. Streaming Analytics is correctly referred to as Perishable … Continue reading Use Streaming Analytics to Identify and Visualise Fraudulent ATM Transactions in Real-Time
UDFs in KSQL: DateAdd
KSQL, the SQL engine for streaming data, is a very powerful tool that helps great deals in Streaming Analytics use cases. It comes with a set of functions that could be used to transform, filter or aggregate data and the good thing is that you can extend it easily by implementing and adding your own … Continue reading UDFs in KSQL: DateAdd
AWS Glue Part 3: Automate Data Onboarding for Your AWS Data Lake

Choosing the right approach to populate a data lake is usually one of the first decisions made by architecture teams after deciding the technology to build their data lake with. A recent trend seems to be taking over is using Spark, since it’s fast and powerful and comes with a lot of flexibilities when used … Continue reading AWS Glue Part 3: Automate Data Onboarding for Your AWS Data Lake
AWS Glue Part 2: ETL your data and query the result in Athena
In part one of my posts on AWS Glue, we saw how Crawlers could be used to traverse data in s3 and catalogue them in AWS Athena. Glue is a serverless service that could be used to create ETL jobs, schedule and run them. In this post we'll create an ETL job using Glue, execute … Continue reading AWS Glue Part 2: ETL your data and query the result in Athena
AWS Glue Part 1: Discover and Catalogue Data Stored in s3

Learn how to add a Crawler in AWS Glue for data that is stored in s3
Airflow & Celery on Redis: when Airflow picks up old task instances
This is going to be a quick post on Airflow. We realized that in one of our environments, Airflow scheduler picks up old task instances that were already a success (whether marked as success or completed successfully). You can verify this is actually your issue by ssh into your Airflow workers, and run: ps -ef … Continue reading Airflow & Celery on Redis: when Airflow picks up old task instances
How to import spark.implicits._ in Spark 2.2: error “value toDS is not a member of org.apache.spark.rdd.RDD”
I wrote about how to import implicits in spark 1.6 more than 2 years ago. But things have changed in Spark 2.2: the first thing you need to do when coding in Spark 2.2 is to set up an SparkSession object. SparkSession is the entry point to programming Spark with DataSet and DataFrame. Like Spark … Continue reading How to import spark.implicits._ in Spark 2.2: error “value toDS is not a member of org.apache.spark.rdd.RDD”
Spark Error “java.lang.IllegalArgumentException: Size exceeds Integer.MAX_VALUE” in Spark 1.6
RDDs are the building blocks of Spark and what make it so powerful: they are stored in memory for fast processing. RDDs are broken down into partitions (blocks) of data, a logical piece of distributed dataset. The underlying abstraction for blocks in Spark is a ByteBuffer, which limits the size of the block to 2 … Continue reading Spark Error “java.lang.IllegalArgumentException: Size exceeds Integer.MAX_VALUE” in Spark 1.6
Spark Error CoarseGrainedExecutorBackend Driver disassociated! Shutting down: Spark Memory & memoryOverhead
Another common error we saw in yarn application logs was this: 17/08/31 15:58:07 WARN CoarseGrainedExecutorBackend: An unknown (datanode-022:43969) driver disconnected. 17/08/31 15:58:07 ERROR CoarseGrainedExecutorBackend: Driver 10.1.1.111:43969 disassociated! Shutting down. Googling this error suggests increasing spark.yarn.driver.memoryOverhead or spark.yarn.executor.memoryOverhead or both. That has apparently worked for a lot of people. Or at least those who were smart enough to understand … Continue reading Spark Error CoarseGrainedExecutorBackend Driver disassociated! Shutting down: Spark Memory & memoryOverhead
