Everything changes and nothing stays still. Even the source systems generating data across the organisations (shocking!!), which means the schema of the downstream data stores need to evolve accordingly. Schema evolution refers to the ability of downstream systems such as data warehouses to be able to adapt to the changes in the structure of data they receive from sources generating the data.
Data in cloud platforms is usually stored in multiple storage services: the object storage where data is stored as files as well as somewhere to allow querying data using SQL. (Of course, in some cases data is not actually stored in the second layer and files stored in object storage are queried using external tables.) In this post, I am going to explain a method to automate schema evolution of tables created in BigQuery, based on the changes in the schema that is stored in a Firestore collection.
I have created a table in BigQuery that looks like this:
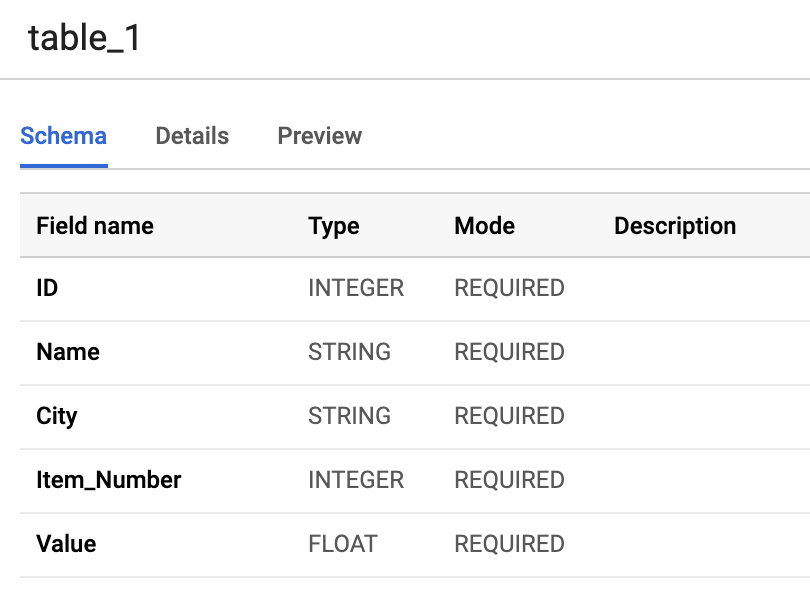
To be able to automate schema evolution on Google Cloud Platform from GCS to BigQuery, we need to have the schema of the BigQuery tables stored in Firestore, which is the document database available on GCP. I went ahead and created a collection in Firestore and stored the my table’s schema in there:
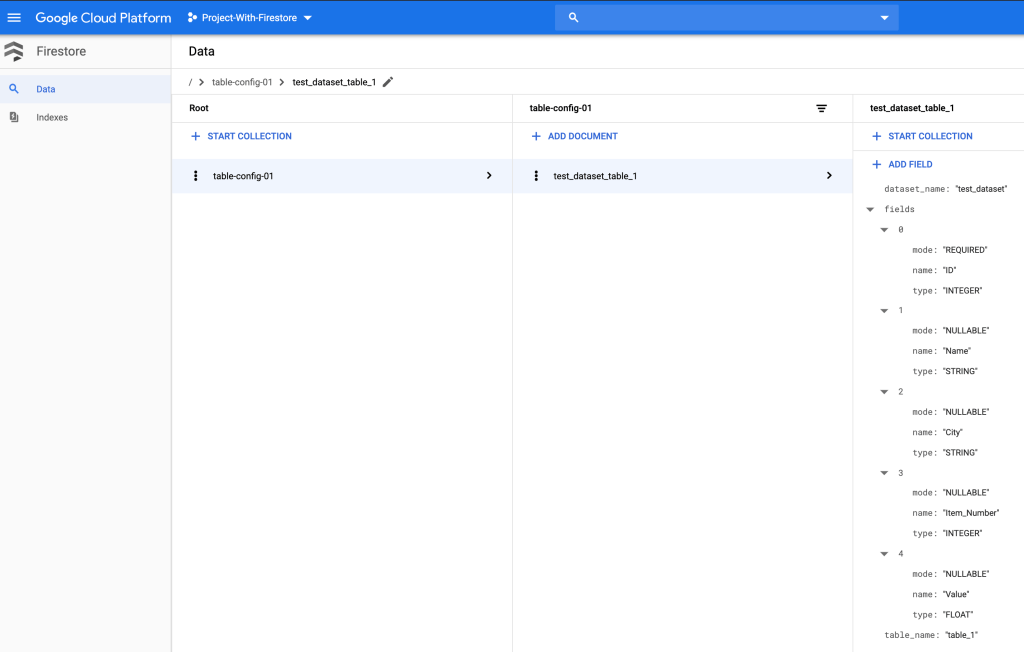
Now that we have our table in BigQuery and its schema loaded in Firestore, we can implement a solution that detects if new columns are added to the schema stored in Firestore collection and alter table in BigQuery to have them added as NULLABLE columns. (Can you tell why the new columns need to be nullable?)
We’re going to do this using Python, everyone’s favourite programming language (I am still a massive Scala fan though):
Retrieve table config from Firestore
def get_table_configuration(collection, document): db = firestore.Client() doc_ref = db.collection(collection).document(document) data = doc_ref.get().to_dict() return data
This is a self-explanatory function: it gets the collection and document names as input and returns the content of the document.
Extract table schema from BigQuery
def extract_table_schema(dataset_id,table_id): dataset_ref = client.dataset(dataset_id, project=project_id) table_ref = dataset_ref.table(table_id) table = client.get_table(table_ref) return table.schema
The function that takes in BigQuery dataset_id and table_id (names) and returns the schema.
Patch table
We also need a method that patches the table for us with the new column added to the config. For this we can use BigQuery table.update method. Note that table.update only works when there is a new column added to the schema, it’ll fail if any of the existing columns are removed:
def patch_table(bq, dataset_id, table_id, fields): tables = bq.tables() table_reference = {'projectId':project_id, 'tableId':table_id, 'datasetId': dataset_id} table_reference = {"tableReference": table_reference} table_reference.update(fields) tableStatusObject =tables.update( projectId=project_id,\ datasetId=dataset_id,\ tableId=table_id, \ body=table_reference).execute() print "\n\nTable Patched"
It’s worth mentioning that the “fields” parameter passed to the method should be a JSON with the following format:
{ "tableReference": { "projectId": "project_id", "tableId": "table_id", "datasetId": "dataset_id", }, "schema": { "fields": [ { "name": "column_name", "type": "column_type", "mode": "REQUIRED/NULLABLE" }, ... ] } }
Compare schema and config
Now that we have our table’s current and to be schemas, we can easily compare the 2 and patch our table if there is any columns to be added to it. It’s just a matter of getting the list columns from Firestore as well as BigQuery table, loop through the ones in the Firestore and check if they already exist in the table. If there is any new columns, then build up the JSON in the format mentioned above and call the patch_table method:
def main(): table_config = get_table_configuration("collection_name","document_name") table_config_list = list( map( lambda column: bigquery.SchemaField(column["name"], column["type"]), table_config["fields"], ) ) dataset_id = 'dataset_id' table_id = 'table_id' table_schema = extract_table_schema(dataset_id, table_id) new_fields = [] for c in table_config_list: i = 0 for s in table_schema: if c.name.lower() == s.name.lower(): i = 1 break if i == 0: new_fields.append(c) if len(new_fields) == 0: print("New field(s) to be added to the table") credentials = GoogleCredentials.get_application_default() bq = discovery.build('bigquery', 'v2', credentials=credentials) table_config = {'fields':table_config['fields']} table_config = {'schema':table_config} patch_table(bq, dataset_id, table_id, table_config)
Automate it
The code we developed together here should be called and executed when loading from GCS to BigQuery. There are multiple ways of deploying it, depending on the mechanism used to load BigQuery tables. One could be to deploy it as a Google Cloud Function and call it as part of the load, as the very first step. All that needs to change is the main method and replacing it with another method that takes is a HTTP request, extracts dataset_id and table_id from it and calls the rest of the logic with them.
