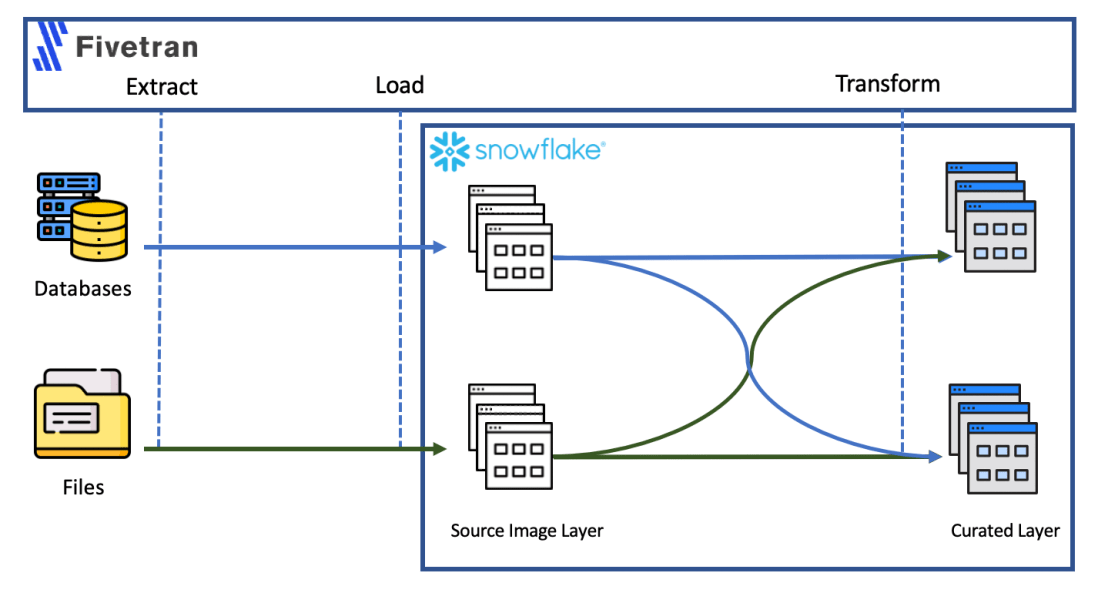
Cloud has become the default choice for many organisations when they decide to build a data platform or modernise their existing ones. Cloud data platforms are so ubiquitous nowadays that even those who used to emphasise on imaginary terms such as "vendor lock-in" can't defend building an on-premise platform from scratch anymore. But not all … Continue reading Acquire and historicise data into Snowflake using Fivetran
Category: Big Data
Control IoT Devices Using Scala on Databricks (Based on ML Model Output)

A few weeks ago I did a talk at AI Bootcamp here in Melbourne on how we can build a serverless solution on Azure that would take us one step closer to powering industrial machines with AI, using the same technology stack that is typically used to deliver IoT analytics use cases. I demoed a … Continue reading Control IoT Devices Using Scala on Databricks (Based on ML Model Output)
Stream IoT sensor data from Azure IoT Hub into Databricks Delta Lake

IoT devices produce a lot of data very fast. Capturing data from all those devices, which could be at millions, and managing them is the very first step in building a successful and effective IoT platform. Like any other data solution, an IoT data platform could be built on-premise or on cloud. I'm a huge … Continue reading Stream IoT sensor data from Azure IoT Hub into Databricks Delta Lake
From Monolithic Architecture to Microservices and Event-Driven Systems

I’m a massive fan of streaming and real time data processing and solutions. I strongly believe a lot of use cases are going to be defined and implemented around fast and streaming data in near future, especially in IoT and streaming analytics. With 5G rolling out soon and its superfast bandwidth and wide geographical coverage, … Continue reading From Monolithic Architecture to Microservices and Event-Driven Systems
UDFs in KSQL: DateAdd
KSQL, the SQL engine for streaming data, is a very powerful tool that helps great deals in Streaming Analytics use cases. It comes with a set of functions that could be used to transform, filter or aggregate data and the good thing is that you can extend it easily by implementing and adding your own … Continue reading UDFs in KSQL: DateAdd
How to import spark.implicits._ in Spark 2.2: error “value toDS is not a member of org.apache.spark.rdd.RDD”
I wrote about how to import implicits in spark 1.6 more than 2 years ago. But things have changed in Spark 2.2: the first thing you need to do when coding in Spark 2.2 is to set up an SparkSession object. SparkSession is the entry point to programming Spark with DataSet and DataFrame. Like Spark … Continue reading How to import spark.implicits._ in Spark 2.2: error “value toDS is not a member of org.apache.spark.rdd.RDD”
Spark Error “java.lang.IllegalArgumentException: Size exceeds Integer.MAX_VALUE” in Spark 1.6
RDDs are the building blocks of Spark and what make it so powerful: they are stored in memory for fast processing. RDDs are broken down into partitions (blocks) of data, a logical piece of distributed dataset. The underlying abstraction for blocks in Spark is a ByteBuffer, which limits the size of the block to 2 … Continue reading Spark Error “java.lang.IllegalArgumentException: Size exceeds Integer.MAX_VALUE” in Spark 1.6
Spark Error CoarseGrainedExecutorBackend Driver disassociated! Shutting down: Spark Memory & memoryOverhead
Another common error we saw in yarn application logs was this: 17/08/31 15:58:07 WARN CoarseGrainedExecutorBackend: An unknown (datanode-022:43969) driver disconnected. 17/08/31 15:58:07 ERROR CoarseGrainedExecutorBackend: Driver 10.1.1.111:43969 disassociated! Shutting down. Googling this error suggests increasing spark.yarn.driver.memoryOverhead or spark.yarn.executor.memoryOverhead or both. That has apparently worked for a lot of people. Or at least those who were smart enough to understand … Continue reading Spark Error CoarseGrainedExecutorBackend Driver disassociated! Shutting down: Spark Memory & memoryOverhead
Spark Error: Failed to Send RPC to Datanode
This past week we had quite few issues with users not being able to run Spark jobs running in YARN Cluster mode. Particularly a team that was on tight schedule used to get errors like this all the time: java.io.IOException: Failed to send RPC 8277242275361198650 to datanode-055: java.nio.channels.ClosedChannelException Mostly accompanied by error messages like: org.apache.spark.SparkException: Error … Continue reading Spark Error: Failed to Send RPC to Datanode
YARN Capacity Scheduler: Queue Priority
Capacity Scheduler is designed to run Hadoop jobs in a shared, multi-tenant cluster in a friendly manner. Its main strength is that it guarantees specific capacity for a certain group of users by supporting multiple queues and allowing users to submit their queries into their dedicated queues. Each queue is given a fraction of total … Continue reading YARN Capacity Scheduler: Queue Priority
Hive Performance Tuning
If you have been working in Big Data, you have definitely heard of Hive. Apache Hive is the data warehouse infrastructure build on top of Hadoop. I did a presentation on how to best use Apache Hive and few tips on how to best use it for one of our clients last week that I … Continue reading Hive Performance Tuning
Hadoop Error org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block
Like almost all Mondays, today was a very challenging one. The first thing I noticed was that our primary namenode had faced some issues over the weekend and went down. Which means secondary namenode, namenode-02, was active. I checked namenode-01 and made sure it is okay before making it active again. After that, I was made … Continue reading Hadoop Error org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block
How to import org.apache.spark.sql.SQLContext.implicits in Spark 1.6: error “value toDF is not a member of org.apache.spark.rdd.RDD”
Note: If you're using Spark 2.2, please read this post I am doing a mini project for my company using Spark/Scala and have been stuck with the error mentioned in the title for a couple of days. Googling that error suggested to import org.apache.spark.sql.SQLContext.implicits, and that's what I did: import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.sql._ import … Continue reading How to import org.apache.spark.sql.SQLContext.implicits in Spark 1.6: error “value toDF is not a member of org.apache.spark.rdd.RDD”
