Cloud has become the default choice for many organisations when they decide to build a data platform or modernise their existing ones. Cloud data platforms are so ubiquitous nowadays that even those who used to emphasise on imaginary terms such as “vendor lock-in” can’t defend building an on-premise platform from scratch anymore.
But not all cloud platforms are equal. Moving to cloud offers a chance to reset and if you’re provisioning 10s of VMs and installing the same software (databases, web applications, firewalls, etc.) on them, you’re doing cloud wrong. The main benefits of moving to cloud are lowering the cost and freeing up resources in operations teams (who take care of day to day activities such as installing and upgrading software, patching servers and replacing stale hardware), as well as the higher level of business agility that comes as a result of being able to deliver and respond to changes in the market faster. That’s why many organisations are on the journey to upgrade their tech stacks to cloud-native and serverless services. (I’m going to refer to all cloud services that do not need provisioning of VMs as serverless, including FaaS, PaaS, and SaaS service offerings)
In this post, I will show how you can build a data warehouse on the cloud and set up proper ELT jobs to acquire and historicise data in SCD-2 tables in Snowflake using Fivetran. A complete Serverless stack, with best of breed tech stack available in the market right now.
Snowflake
Snowflake is one of those products that was built for cloud from scratch. I started my data warehousing days with SQL Server back in the previous decade, and then worked with some MPPs as the database engines hosting the data warehouse (separation of storage from compute was non-existent in those days). My line of work took me away from designing and building data warehouses for few years, until toward the end of last year when I was asked to lead a team building a data warehouse on GCP and then doing the same thing on AWS.
There are 2 main options to build a data warehouse on AWS, Redshift and Snowflake. Although I have seen it being done on RDS as well, but that’s certainly not the right choice. We decided to go with Snowflake since many people have good things to say about it and most of our clients have chosen it as their data warehouse platform. And I must say it delivered so well:
- It’s unbelievably easy to set it up and get started. All you need to do is to go to https://trial.snowflake.com/ , register an account and you can start playing around and see what the fuss is about for yourself
- It’s very performant and easy to adjust for different workloads, thanks to its unique 3 layer architecture. I’m not going into too much details about it, read more here
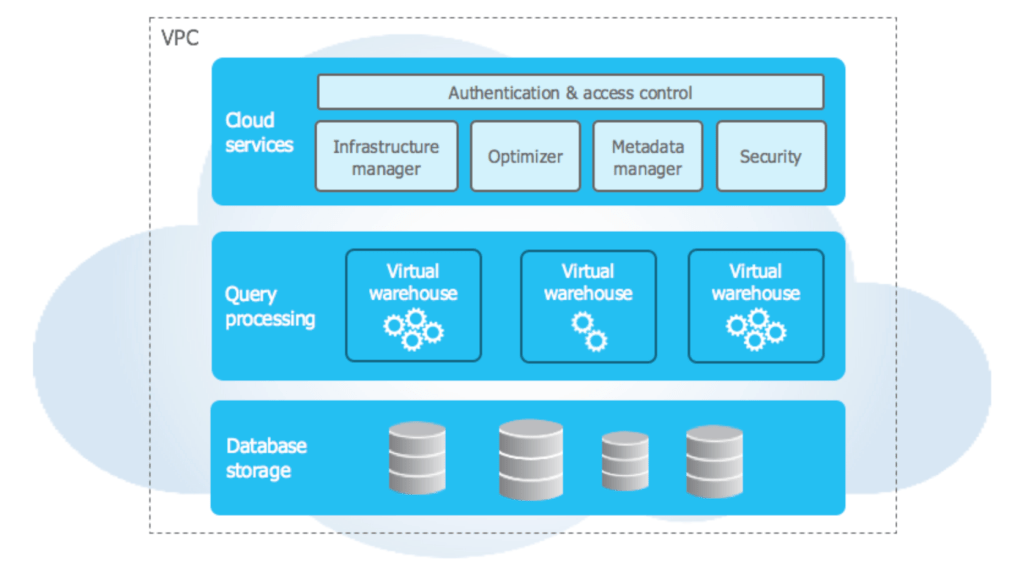
- Supports structured and semi-structured data all in one place, enabling analytics teams to work with a wider range of datasets by connecting to one single data repository.
- It is always available, thanks to Snowflake’s distributed architecture across multiple AZs. When I decided to go ahead with Snowflake, I was a bit concerned about the cold start and how it might affect queries. But I can tell you that we didn’t experience any noticeable delays when ingestion or analytics jobs started.
IMPORTANT: After you registered your account with Snowflake, make sure to follow the instructions in here to have it ready for Fivetran.
Fivetran
Fivetran offers fully managed data pipelines as a service. Like other as-a-service technologies, it doesn’t require configuration or maintenance on the consumer side. It uses custom made connectors to acquire data from source systems into ready to query schema in the data warehouse of your choice such as Snowflake or BigQuery. Getting started with Fivetran is as easy as it is with Snowflake: just head to https://fivetran.com/signup, register an account and you’re ready to go. Fivetran encrypts data end to end and there is no data retention in Fivetran’s servers whatsoever.
With Fivetran, we create ELT data pipelines. These pipelines will load source data directly into the data warehouse and then transformation scripts run down on the warehouse to get data ready for for analysis or reporting . The diagram below sheds some light on how it all works and how it is different from ETL:
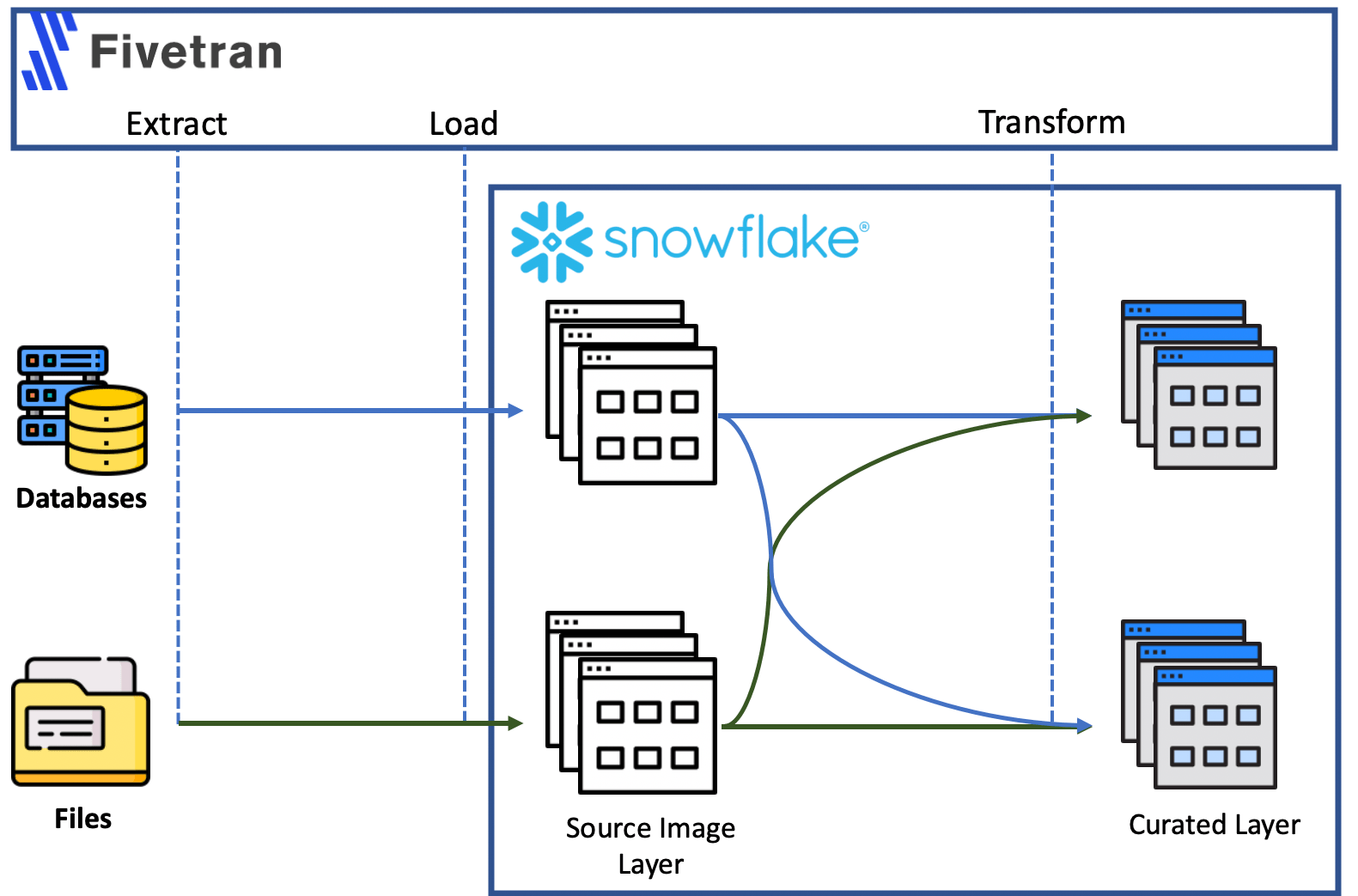
- Data is extracted from data sources such as databases, file storage or events producers
- It is ingested into the tables in Source Image layer in Snowflake, exactly in the same format they were extracted from source. No data manipulation happens here and tables in source image schema mirror data in source systems
- Data transformation is done by SQL scripts that are pushed down and executed in the data warehouse engine. Here we can combine data from multiple sources (the classic example of customer information coming from financial and marketing systems which needs to be cleansed and combined into a single table) in the table in curated schema, having it ready for reporting or analysis
Fivetran makes data acquisition into cloud so easy: all you need to do is to setup a destination warehouse, a connector, a transformation and proper schedule the data acquisition and transformation pipelines. It will run the jobs, acquire data into the destination and transform them, and send emails on the outcome of the jobs when they finish.
For the rest of this post, I’ll take you through the steps to acquire data from MySQL (on AWS RDS) into Snowflake and historicise it in there into Slowly Changing Dimension tables.
Connect Fivetran to Snowflake
After logging in to Fivetran, the very first step is to set up the destination warehouse. You’ll see 2 options right in the middle of the page: you already have a warehouse you want to connect to or you want to have it created for you. If you followed the steps listed in Fivetran’s website here, you already have a warehouse in Snowflake. So click on the first option. In the next page, click on Snowflake. Fill in the required fields in the page and click on Save & Test. Upon successful test of the connection, click on View Destination.
Setup RDS
For Fivetran to be able to connect and work with RDS, you need to follow the steps listed here to:
- Enable Fivetran’s access to RDS: By whitelisting Fivetran’s IP range
- Create a user to access MySQL database
- Configure Parameter Groups and change binlog_format to ROW to have row-based binary logging for MySQL
We’re going to need a sample database to work with, so go ahead and download classicmodels database from: https://www.mysqltutorial.org/mysql-sample-database.aspx/
Acquire data from RDS into Snowflake
We are ready to connect to RDS and ingest the data from the database we restored in our MySQL database to Snowflake.
Create a Fivetran RDS Connector
To connect to database on RDS, open Fivetran’s warehouse page, click on “Connectors” on the left pane and then click on “Create your first connector” or “+Connector”:

Search for MySQL and select “MySQL RDS” from the list:
In the next page, you’ll get to configure your new connector:
- Destination schema prefix: This is the prefix that will be added to the name of schema created in Snowflake
- Host: The writer endpoint of your RDS instance
- Port: The port to connect to, 3306 by default for RDS MySQL
- User: RDS username you created when setting it up
- Password: RDS password
- Connection Method: Specify whether to connect to your RDS database directly or you want Fivetran to go via another server if RDS is in a private subnet
So go ahead and fill in the fields for your RDS database instance and then click on Save & Test:
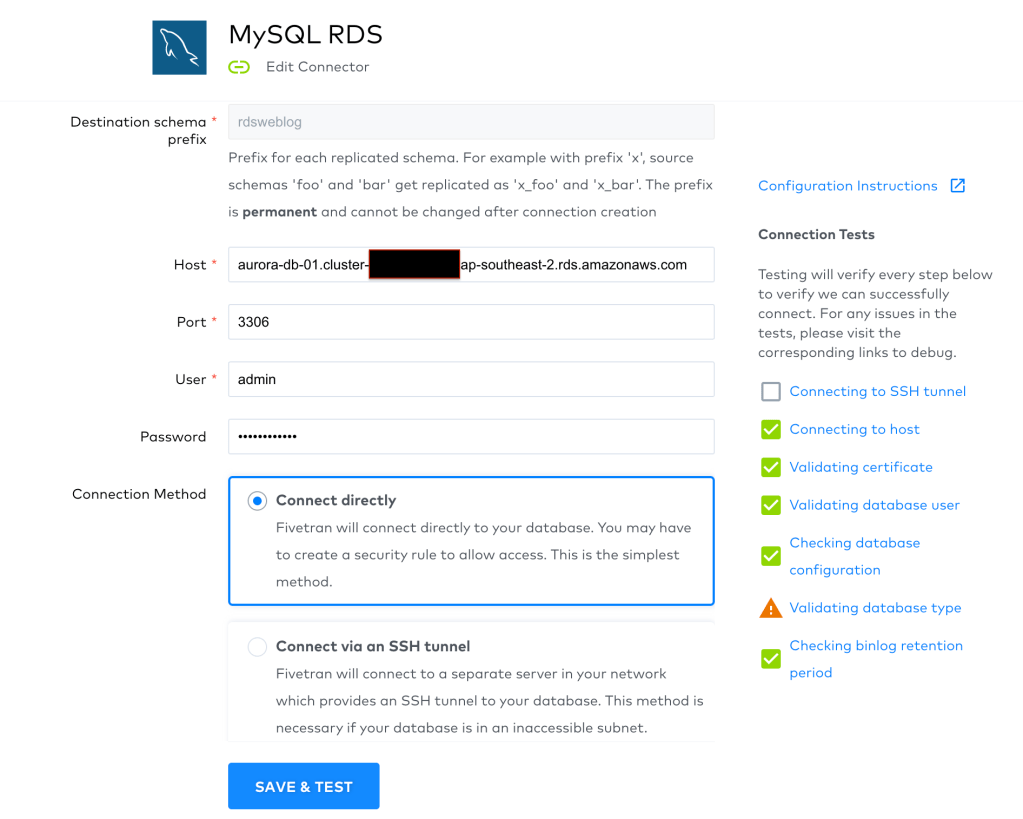
All is green and good, except that I started getting a warning for database type recently. Not sure why though, I am confident I am using the right connector. Also, you may get the prompt to confirm which TLS certificate to use. I didn’t notice any differences when used one or another, so chose the top one.
Click on View Connector on the top left side of the page. You will see the following tabs:
- Status: You can check sync history, alerts, stats and user actions in this tab
- Logs: Logs for your data pipeline’s past runs appear here
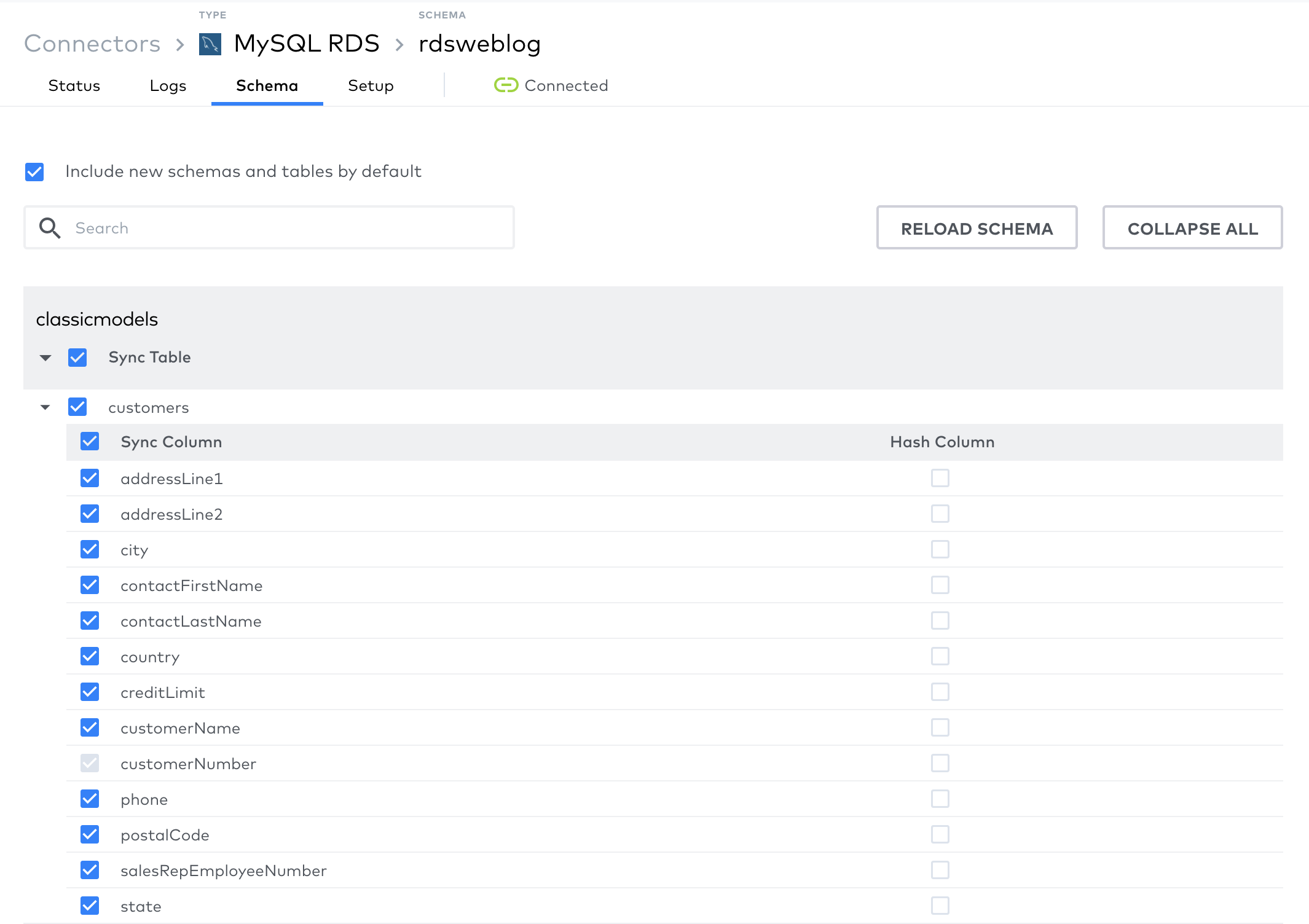
- Schema: This is an interesting and important tab.
- You can see the list of tables in your source database here together with their columns.
- You can select/un-select the tables/columns you want to be acquired into your destination warehouse here, with the exception being the primary key of the tables. What it means is that if you’re selecting a table, you have to acquire at minimum its primary key into destination. Why is that so? Because Fivetran needs tables’ primary keys to determine which rows are deleted or updated since its last run. You’ll see how this feature comes very handy when we’re setting up our transformation.
- You can check the latest source schema by clicking on “Reload Schema” button.
- Also, notice “Include new schemas and tables by default” checkbox. When selected, Fivetran will sync new schemas and tables automatically into destination warehouse
- Setup: Another important tab. Here you can:
- See the details of the connection created to source database
- Set sync frequency, from every 5 minutes to every 24 hours
- And re-sync the data from source

Enable The Data Pipeline
We’re ready to un-pause our data pipeline and have it run on the schedule we set:

Now go to logs tab and check log entries as data is loaded into your destination warehouse from source RDS database. You would be able to see new tables created and populated in Snowflake when Fivetran data pipeline finishes successfully.
Historicise Data in Snowflake: Implement Slowly Changing Dimensions
Now that we have our source data ingested in Snowflake, we can move to the next step and apply the principles of slowly changing dimension type-2 by using Fivetran transformations. You are most probably familiar with what SCDs are if you’re reading this post, let’s go through what our transformation needs to do to implement them (We are going to track history with 3 additional columns in the table in curated layer, namely effective_from, effective_to, and is_current):
- The new records in the source database that are inserted in source image table since last time Fivetran transformation ran, should be inserted into table in curated layer with:
- effective_from = current time
- effective_to = 31/12/2999
- is_current = true
- For the records that were deleted in source database since last time data transformation ran, Fivetran will soft-delete them in source image layer (we’ll see more on this later). These records should be outdated in curated layer by setting:
- effective_to = current_time
- is_current = false
- For the records that were changed in source database and therefore updated in source image layer since last time Fivetran transformation ran:
- The existing record in curated layer should be outdated by setting:
- effective_to = current time
- is_current = false
- A new record should be inserted into curated layer with the new values, having:
- effective_from = current time
- effective_to = 31/12/2999
- is_current = true
- The existing record in curated layer should be outdated by setting:
In the remaining sections of this post we will add the required components in Snowflake and Fivetran to implement the logic explained above for table Customers.
Add a new schema to Snowflake
The first step is to add a new schema to Snowflake where the historicised tables are going to reside. Run the following code in a worksheet:
use "FIVETRAN_WEBLOG";
CREATE SCHEMA CLASSICMODELS_CURATED;And grant all privileges to Fivetran role on the new schema:
grant all privileges on schema CLASSICMODELS_CURATED to role fivetran_role;
grant all privileges on future tables in schema CLASSICMODELS_CURATED to role fivetran_roleAdd target table
Next, we need to create a table in the target schema in Snowflake. This table should match its corresponding table in the Source Image schema, and have the extra columns required for tracking changes in a SCD-2 implementation: effective_from, effective_to, is_current.
To get the DDL for the the tables in source image layer created by Fivetran use GET_DDL:
SELECT GET_DDL('table', 'FIVETRAN_WEBLOG.RDSWEBLOG_CLASSICMODELS.CUSTOMERS');The DDL we’re looking for curated table Customers is as follows:
CREATE OR REPLACE TABLE "FIVETRAN_WEBLOG"."CLASSICMODELS_CURATED"."CUSTOMERS" (
CUSTOMERNUMBER NUMBER(38,0),
CUSTOMERNAME VARCHAR(50),
CONTACTLASTNAME VARCHAR(50),
CONTACTFIRSTNAME VARCHAR(50),
PHONE VARCHAR(50),
ADDRESSLINE1 VARCHAR(50),
ADDRESSLINE2 VARCHAR(50),
CITY VARCHAR(50),
STATE VARCHAR(50),
POSTALCODE VARCHAR(15),
COUNTRY VARCHAR(50),
SALESREPEMPLOYEENUMBER NUMBER(38,0),
CREDITLIMIT NUMBER(10,2),
EFFECTIVE_FROM DATETIME DEFAULT to_timestamp_ltz(current_timestamp()),
EFFECTIVE_TO DATETIME DEFAULT to_timestamp('2999-12-31 00:00:00'),
IS_CURRENT BOOLEAN DEFAULT true
);Note the DEFAULT values for the 3 columns tracking history.
Create change status view
We’re going to create a view in source image schema to help us figure out how to transform and historicise data into curated tables. Note that the tables in source image will always hold all the rows ever extracted from the source database (existing records are NOT deleted before data pipelines run). Therefore, our transformation should be able to work on the records that were changed or inserted since last time Fivetran ran the transformation script. Also, note that Fivetran will soft-delete records in source image table that were deleted in the source database.
The following 2 columns that are managed by Fivetran help us figure out the current state of each row:
- _FIVETRAN_DELETED: A boolean column that is set to true when Fivetran detects a row is deleted from source table (soft delete)
- _FIVETRAN_SYNCED: A timestamp column that records the last time a row was changed (updated or deleted) in source
Our view will have all the columns from the table with 2 additional ones:
- CHANGE_STATUS: A flag that will tell us if a row was deleted (‘D’), Updated (‘U’), Inserted (‘I’) or unchanged (‘N’) in the source system, as of when Fivetran job last ran
- DUMMY_DATE: A timestamp with 2 possible values, current time or a time that will never fall in the time window between Fivetran data pipeline runs. I chose ‘1999-01-01 00:00:00.000’
The view SQL code is below, let’s go through what it actually does. To specify which records were deleted since last time Fivetran ELT data pipeline ran, we look for those with _FIVETRAN_DELETED = true and _FIVETRAN_SYNCED in the time window between last and current runs, in my case 5 minutes. Similarly, updated records are the ones with _FIVETRAN_DELETED = false and _FIVETRAN_SYNCED in the time window between last and current runs, and the rest are unchanged. For all these records we set DUMMY_DATE to be the current time.
For the records that are updated in the source, we need to insert a new one in the curated table with the current column values that is valid for future analysis (refer to start of this section, implementing Slowly Changing Dimensions). That’s why we have the UNION clause, selecting updated rows from the table with DUMMY_DATE set to 1999, to make sure they won’t fall within the time window of current or future Fivetran runs. This is required since we’re going to use Snowflake MERGE command as our transformation script, more on this below.
Before we add the view, let’s make sure Fivetran role will have necessary privileges to be able to work with it:
grant all privileges on future views in schema "FIVETRAN_WEBLOG"."RDSWEBLOG_CLASSICMODELS" to role fivetran_roleAnd now run the following SQL code to have the view created:
CREATE OR REPLACE VIEW "FIVETRAN_WEBLOG"."RDSWEBLOG_CLASSICMODELS"."CUSTOMERS_CHANGE_STATUS" AS
SELECT *,
CASE WHEN _FIVETRAN_DELETED = true
AND DATEDIFF(minute, _FIVETRAN_SYNCED, convert_timezone('UTC',current_timestamp())) <= 5
THEN 'D'
WHEN _FIVETRAN_DELETED = false
AND DATEDIFF(minute, _FIVETRAN_SYNCED, convert_timezone('UTC',current_timestamp())) <= 5
THEN 'U'
ELSE 'N'
END AS CHANGE_STATUS,
to_timestamp_ntz(current_timestamp()) AS DUMMY_DATE
FROM "FIVETRAN_WEBLOG"."RDSWEBLOG_CLASSICMODELS"."CUSTOMERS"
UNION
SELECT *,
CASE WHEN _FIVETRAN_DELETED = false
AND DATEDIFF(minute, _FIVETRAN_SYNCED, convert_timezone('UTC',current_timestamp())) <= 5
THEN 'I'
ELSE 'N'
END AS CHANGE_STATUS,
'1999-01-01 00:00:00.000'::timestamp AS DUMMY_DATE
FROM "FIVETRAN_WEBLOG"."RDSWEBLOG_CLASSICMODELS"."CUSTOMERS"IMPORTANT: Note that the value you choose to compare with the result of DATEDIFF should match the schedule at which your data pipeline runs. I set my job to run every 5 minutes so that I can test my logic quicker, which might be different from your requirements. Set this properly, otherwise the logic implemented in the view will be broken and you will end up with duplicate records in curated layer.
Add a transformation in Fivetran
With Fivetran, we create ELT data pipelines that push data transformations down to the destination data warehouse to be executed. Click on the Transformations from the left pane on the Warehouse page and then click on blue “+ Transformation” button in the middle of the page. Here we need to provide the following information:
- Name
- SQL Script: The code to transform data from Source Image layer to Curated layer. For us, this is the SQL script that implements a SCD Type-2
- Schedule Type: Interestingly, Fivetran provides the option to run the transformation SQL script when new data arrives in the source table just like a trigger, as well as having it run on a schedule.
The SQL Script we will have running on Snowflake will use Merge command to detect inserted, updated and deleted rows in the source image layer with help from the view we created, and track the change history in table in curated schema. I highly recommend you to read more about Snowflake’s Merge command here, specially on the insert part to understand why I set DUMMY_DATE the way I do and what the role of UNION in the view is. Go ahead and copy the code below and paste it as the transformation SQL Script:
merge into "FIVETRAN_WEBLOG"."CLASSICMODELS_CURATED"."CUSTOMERS" target_table
using "FIVETRAN_WEBLOG"."RDSWEBLOG_CLASSICMODELS"."CUSTOMERS_CHANGE_STATUS" source_table
on target_table.CUSTOMERNUMBER = source_table.CUSTOMERNUMBER
and source_table.DUMMY_DATE BETWEEN target_table.EFFECTIVE_FROM and target_table.EFFECTIVE_TO
when matched
and source_table.CHANGE_STATUS = 'D' then
update set target_table.EFFECTIVE_TO = convert_timezone('UTC',to_timestamp_ltz(current_timestamp())),
target_table.IS_CURRENT = false
WHEN matched
and source_table.CHANGE_STATUS = 'U' then
update set target_table.EFFECTIVE_TO = convert_timezone('UTC',to_timestamp_ltz(current_timestamp())),
target_table.IS_CURRENT = false
WHEN not matched
and source_table.CHANGE_STATUS = 'I' then
insert (CUSTOMERNUMBER,CUSTOMERNAME,CONTACTLASTNAME,CONTACTFIRSTNAME,PHONE,ADDRESSLINE1,ADDRESSLINE2,CITY,STATE,POSTALCODE,COUNTRY,SALESREPEMPLOYEENUMBER,CREDITLIMIT,EFFECTIVE_FROM)
VALUES (source_table.CUSTOMERNUMBER, source_table.CUSTOMERNAME, source_table.CONTACTLASTNAME, source_table.CONTACTFIRSTNAME, source_table.PHONE, source_table.ADDRESSLINE1, source_table.ADDRESSLINE2, source_table.CITY, source_table.STATE, source_table.POSTALCODE, source_table.COUNTRY, source_table.SALESREPEMPLOYEENUMBER, source_table.CREDITLIMIT, to_timestamp_ntz(current_timestamp()))
;Set the Schedule Type to “New Data” and select Trigger Tables:
Let your jobs run and test them by deleting some records, updating some others and inserting new records into RDS database. And then check the tables in Snowflake, both source image and curated layers, and watch the changes being replicated to your warehouse and historicised.
What’s next
We can use the same process to transform tables from source systems and track history or combine those coming from different source systems and create a single source of truth for an entity (customers, for example, coming from sales and delivery systems separately).
The good folks at Fivetran are expanding their API support so that all of what we saw here in this post can be automated. I personally would like to see support for creating and managing Transformations with APIS soon.
I was very impressed by my evaluation of Fivetran:
- It is very easy to set up
- Performance is unbelievably good, which makes it a perfect match for Snowflake and other managed data warehouse solutions offered on the cloud
- It offers schema evolution out of the box, which is a very important feature required for the ever-changing source systems
- ELT processes are very intuitive and they just make sense. Cloud data warehouses are powerful enough and support a wide range of elasticity, which makes them perfect to run data transformation jobs
- Transformations are applied to the incoming data in near real-time, since the same infrastructure that holds source data will transform it too
- Minimal downtime, since it is managed and we don’t need to worry about servers crashing and having to plan for spikes in number of jobs running simultaneously
- With Fivetran we get logging out of the box, although it is possible to connect it to your choice of log service such as AWS CliudWatch, Azure Log Analytics or Google Stackdriver. Hopefully support for third party logging tools such as Datadog is added soon as well
Go ahead and have a go with it, I’m sure you will be impressed too.
