
I’m a massive fan of streaming and real time data processing and solutions. I strongly believe a lot of use cases are going to be defined and implemented around fast and streaming data in near future, especially in IoT and streaming analytics. With 5G rolling out soon and its superfast bandwidth and wide geographical coverage, it’ll be much easier to capture and move data from devices in different locations to analyse and act upon.
In this post I am going to write about the traditional architecture for system development and why we need a new model, how streaming helped Microservices evolve into event-driven systems and advantages of using Kafka as the central data pipeline across the organisation.
Monolithic Architecture
Monolithic architecture is the traditional design and development approach where monolith application is built as one single unit.
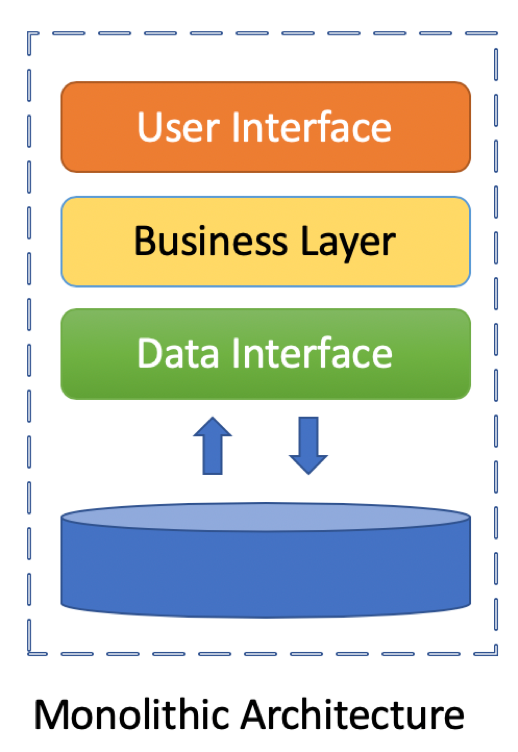
A monolithic application is built in 3 parts:
- A database, consisting of many tables usually in an RDBMS
- A client-side UI, which is where users interact with the application
- A server-side application that handles HTTP requests (by executing some domain specific logic), retrieve data and populate or update the UI
Some of the limitations of Monolithic architecture are:
- Changes to the application are extremely slow: All components are highly coupled, which means changes usually result in a complete overhaul of the application
- There is one code base, every small change result in a completely new release and version of the solution
Microservices Architecture
In a Microservices approach, applications and systems are broken into independent and modular components based on specific business capabilities. These capabilities are defined formally with business-oriented APIs, each of which implementing a specific business logic and function.
Since the function each Microservice provides are independent of each other, the implementation of components are completely hidden from other services as well.

This application of loose coupling minimizes the dependency between services and their consumers. They just need to know the format and type of output provided by the previous application in chain of Microservices and make sure their own output complies with what is expected by the next downstream service, through light-weight protocols. In other words, each Microservice calls the one it has dependency on, gets the result of its operation on the data, and applies the next bit of logic before passing on the result to the next application.
Advantages of Microservices are:
- Isolation and Resilience: If one service fails, another one can be pinned up very quickly. The better approach is to have each layer in HA mode, to minimize the downtime
- Scalability: Each service needs minimal resources and therefore scales easier
- Autonomously Deployed: Upgrade and maintenance becomes very easy and effective through CI/CD
- Relationship to Business: Each business unit owns their Microservices, as opposed a giant usually inefficient IT department
Event-Driven Microservices
Microservices architecture was an evolution of monolithic architecture and came from the realization that the bigger and more complex the systems get, the more inefficient they become and higher their cost of maintenance will be.
When it comes to backend and data storage, each Microservice is expected to have its own space to work, independent of other Microservices it interacts with. There are 2 options to achieve this: 1) Separate databases for each Microservice, 2) Separate schema in the same data store per Microservice.
The first approach is more traditional where multiple instances of, for example, MySQL are created and used by applications. It provides more independent and resilient Microservices, if those instances of database engines run on separate physical servers. The second approach is more modern and is popular among companies with on-premise or cloud-based big data solutions. And it’s resilient from the backend point of view as well, since all big data solutions have some level of replication and high availability incorporated in them.
Modern Microservices are all about making systems event-driven: instead of making remote requests and waiting for the response (services and components calling each other and tell each other what to do), we can send notifications to related microservices when an event occurs.
These events are facts about the business. For example, an ATM or online transaction, a new log entry, or a customer registering for a new mobile plan. They are the data points collected by organizations that make their datasets. The good thing is, we can store these events in the very same infrastructure that we use to broadcast them: Apache Kafka. The better thing is we can even process them in the same infrastructure with Stream Processing applications. This means our applications and systems are linked via this central data pipeline, that is capable of real time data broadcast and processing and all data sources are shared via this data pipeline.
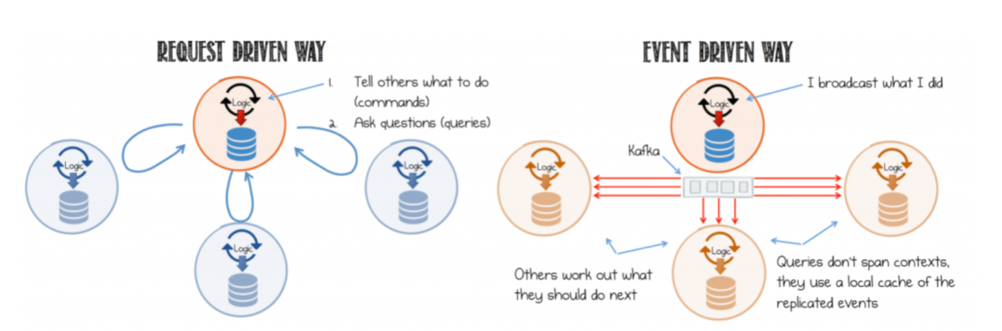
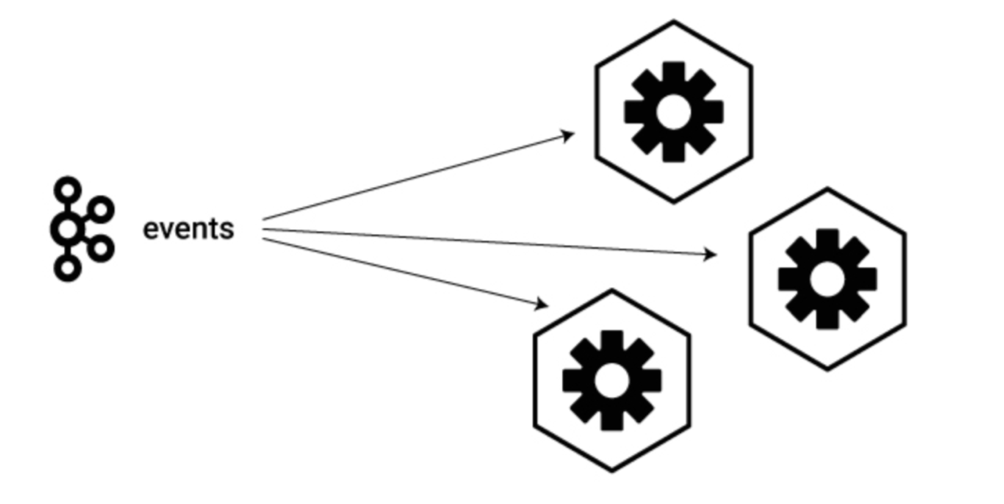
In this architecture, the data that is processed and made ready to be used by applications is kept in Kafka topics and Microservices listen to those topics as the data streams in. When an event lands in a topic, all Microservices that have subscribed to the topic receive the data in real time and act upon it: landing data in a topic is like a notification that goes out to related applications.
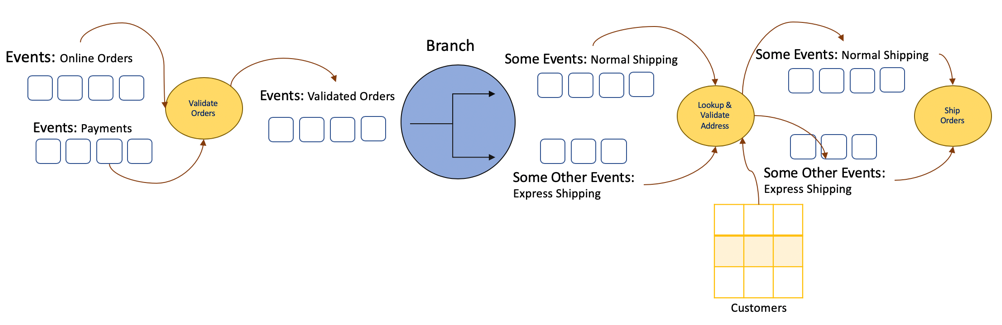
Stream Branching
In the case that some Microservices need to work on a subset of the events in a Kafka topic instead of all of them, it is very inefficient to have them subscribed to the original topic and examine all records to find out which one they need to work on. Instead, we can have a streaming application to branch out the events in the original topic and redirect them to subsequent topics based on their kind. And since stream processing with Kafka is extremely efficient and fast, we get much better performance end to end.
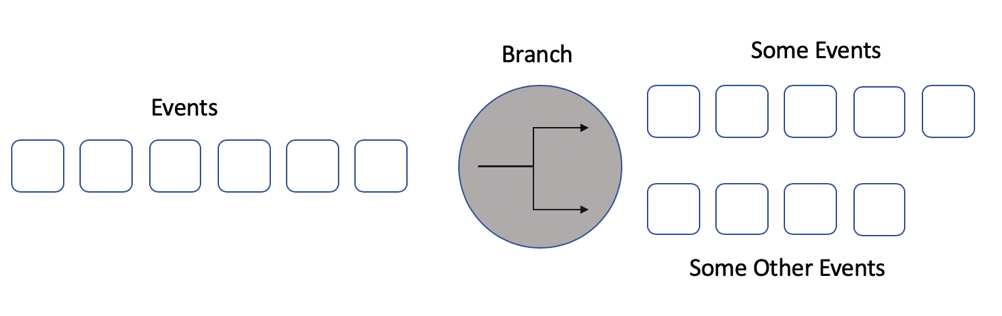
The same principal applies to Microservices’ output as well. They read events from topics, do their things, and write the results back to output topics based on the business logics. And this becomes the chain of Microservices and Kafka topics.
Advantages of Event-Driven Microservices
So far we discussed how Kafka can be used as a source of truth to hold source data, act as the processing engine that transforms, cleanses and branches data and makes it ready to be used by Microservices and applications. This streaming backbone comes with a few other advantages worth mentioning:
High speed
The main use cases where Kafka is used are streaming and real time use cases. The reason is that Kafka is able to provide milliseconds response time needed in those scenarios. And that is the performance we will get all across the organization by using Kafka as the Enterprise Service Bus backbone for our Microservices architecture.
Increased agility and expandability
Having this high performing streaming backbone simplifies development and deployment of new use cases. As a result, the whole organization becomes more agile and able to respond to change as well as expand and answer new questions more efficiently and quickly.
Less pressure on source systems
In this architecture we read data from source systems once and keep them in Kafka topics for different applications to read from. This means all subsequent calls for data are answered by Kafka, not the source systems. And therefore, we don’t interfere with data generators.
Potential for fully asynchronous and non-blocking solutions
Obviously, we were aiming for more Independent and non-blocking applications from the beginning. Breaking down our application into Microservices means the components that build our solution can work at different paces. Also, we can deploy multiple instances of each Microservices component to work on subsets of events in parallel.
Machine Learning and Event-Driven Microservices Architecture
We discussed that events form the datasets an organisation collects and stores. We also discussed why Kafka is the best place to store these events and how it enables more effective Microservices implementation.
At the high level, a machine learning model consists of two different parts: model training and prediction. Training is the stage where historical data is used to learn the patterns within the data and prediction is where the algorithm predicts what’s going to happen based on the newer data.
Kafka and KSQL make machine learning both easy and scalable. Writing SQL statements is probably the easiest way to filter, enrich and transform data and with KSQL we can do that for the events that stream in. As for model training, we can set the retention period of the Kafka topic to a reasonable time period and point the model to those topics to be trained.

And finally, the trained models can be embedded in stream processing applications and deployed as a new Microservice.
What we get from above mentioned approach is an ML model and application that receives events as they stream in and spits out predictions in real time. You can read more about ML in the world of event-driven Microservices here: https://www.confluent.io/blog/using-apache-kafka-drive-cutting-edge-machine-learning
Conclusion
Companies have already started to get away from monolithic architecture because of its high cost of maintenance and upgrade. With Microservices approach, applications are split into small components which are less heavy-weight and focus on specific pieces of business logic. Event-driven architecture took Microservices to the next level and enabled it to respond to incoming events with more agility and flexibility. With Kafka as the backbone of event-driven systems, organisations are able to detect, process and respond to events and even predict the next events in real time.Apache Kafka is much more than a messaging system now, and that’s what progressive companies across the world have realised. It can be used as a message bus, event processing engine and even a fully ACID compliant database, see more here: https://www.youtube.com/watch?v=v2RJQELoM6Y
Resources:
https://www.confluent.io/blog/using-apache-kafka-drive-cutting-edge-machine-learning
https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/
https://www.bmc.com/blogs/microservices-architecture/
https://www.confluent.io/blog/build-deploy-scalable-machine-learning-production-apache-kafka/

One thought on “From Monolithic Architecture to Microservices and Event-Driven Systems”
Comments are closed.