In part one of my posts on AWS Glue, we saw how Crawlers could be used to traverse data in s3 and catalogue them in AWS Athena.
Glue is a serverless service that could be used to create ETL jobs, schedule and run them. In this post we’ll create an ETL job using Glue, execute the job and then see the final result in Athena. We’ll go through the details of the code generated in a later post.
For the purpose this tutorial I am going to use Glue to flatten the json returned by calling Jira API. It’s a long and complex json response, you can see how it looks like here. We had to do it recently at work and it took 2 analysts 2 days to understand the structure and list out all the fields. Using Glue, it’ll take 15 minutes!
Note that if your JSON file contains arrays and you want to be able to flatten the data in arrays, you can use jq to get rid of array and have all the data in JSON format. More about jq here.
Let’s get started:
1. Navigate to AWS Glue console and click on Jobs under ETL in the left hand pane
2. Click on Add job button to kick off Add job wizard
3. Fill up job properties. Most of them are self-explanatory:
a. Provide name.
b. A role that has full Glue access as well as access to the s3 buckets where this job is going to read data from and write results to, as well as save Spark script it generates.
c. Specify whether you’re going to to use Glue interface to develop the basics of your job, have it run an existing script that is already pushed to s3, or start writing the Spark code from scratch.
In this example we’ll select option 1, to have Glue generate the script for us. We get the option to edit it later, if need be.
d. Specify s3 buckets where your script to be saved for future use and where temporary data would be:

4. Select where your source data is. This section lists the tables in Athena databases that the Glue role has access to. We’ll use the table we created in part one:

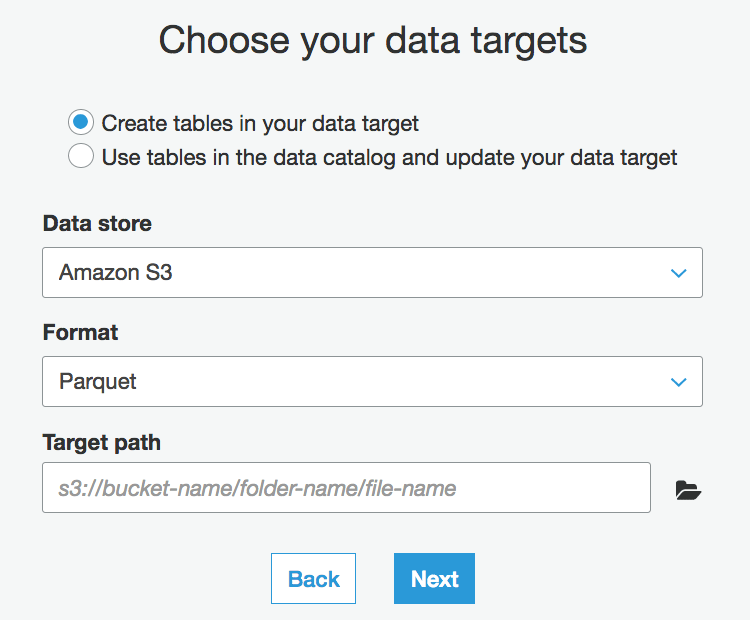
5. Next step? You guessed it right, choosing the target for your ETL job. I want to store the result of my job as a new table, convert my JSON to Parquet (since its faster and less expensive for Athena to query data stored in columnar format) and specify where I want my result to be stored in s3:
6. Here’s the exciting part. Glue matches all the columns in the source table to columns in the target table it’s going to create for us. This is where we can see how our JSON file actually looks like and flatten it by taking columns we’re interested in out of their respected JSON structs:
a. Expand fields, issuetype and project:

b. Remove all the unwanted columns by clicking on the cross button next to them on Target side. W can add the ones that we want to have in our flattened output one by one, by clicking on Add column on top right and then map columns in source to the new ones we just created:

7. Click Finish
8. The next page you’ll see is Glue’s script editor. Here you can review the Spark script generated for you and either run it as it is or make changes to it. For now we’re going to run it as it is. Click on Run job button. You’ll be asked to provide job parameters, put in 10 for the number of concurrent PDUs and click on Run job:

Wait for the job to finish and head to the location in s3 where you stored the result. You’ll see a new file created there for you:

Now that we have our data transformed and converted to Parquet, it’s time to make it available for SQL queries. If you went through my first post on Glue, you’d know the answer is to use Crawlers to create the table in Athena. Follow those steps, create a crawler and have your table available to be queried using SQL. I have done that and this is how my result looks like for what we did together in this document:

Easy, right? You don’t have to worry about provisioning servers, have the right software and version installed on them, and then compete with other applications to acquire resources. That is the power of serverless services offered by cloud providers. Which I personally find very useful, time and cost saving.

2 thoughts on “AWS Glue Part 2: ETL your data and query the result in Athena”
Comments are closed.